
Metis final project - Fishing for Retweets
I presented my final project at Metis last thursday. I talked about using ML to increase the chance that a famous newscaster would retweet me. This post is a work in progress.
Here are my slides.
Motivation
I set out to build a model that would tell me what tweets were likely to get retweeted by specific people. I did not think there would be enough data about most individual users (except maybe Marc Andriessen) to train a model, so I would need to train a model to target a group of users that are presumed to have similar behavior. I targeted political journalists because they’re the gorup I’m most interested in interacting with on twitter. My twitter feed consists of politics and hockey, and hockey players are not very interesting people in conversation.
I focused on Don Lemon in particular because I like the guy, and because his twitter profile describes him as a “Twitter King”. I have been monitoring the twitter traffic of a lot of people for a few weeks, and I beg to differ. Donald John Trump is the king of Twitter, all others are pretenders.
Data
I collected the twitter activity around 108 political reporters and journalists. I got most of the names from the list here, which included 105 names categorized as “Left”, “Center”, or “Right”, and added a few names of my own (Harry Enten, Mike Pesca, Julia Ioffe, and Wikileaks). Andrea Tantaros is on the list, but I had to leave her out because her account is private.
I collected each users’ tweets (including quotes, replies, and retweets), and tweets that mentioned them. The users’ quotes, replies, and retweets were the tweets I was most interested in, because these represent interactions with other users. The tweets mentioning them were my control group, because they were cases where someone started an interaction that was not (usually) reciprocated. Many of the users I tracked got so many mentions that I was not able to collect all of them. Instead, I collected 100 tweets every hour. I was able to estimate the overall rate by seeing how long it took to get 100 tweets. This method gave me hourly and overall estimates of the rates, and I used these estimates to determine the overall probability that each user reacts to a tweet at them. You can see an example of this analysis here.
Time of day
I used the rate of tweets per hour to find the best hour to tweet at each user. Each person has their own daily schedule. The best time to tweet at someone should be the time when they tend to tweet, but they aren’t being deluged by tweets. I computed the ratio of a user’s tweets over their mentions for each hour of the day (hours ending at :45). Here are the results for Don Lemon:
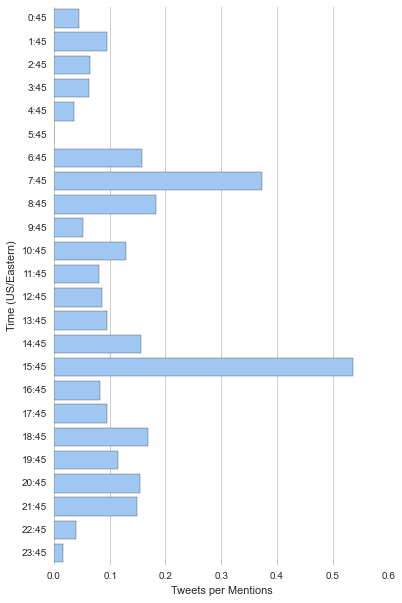 |
3:45 seems to be the best time to tweet at Don Lemon. Unsurprisingly, his probability of responding to a tweet is very low between 10PM and 12AM, when his show is on the air.
Modeling
Tweet Metadata
I used two kinds of metadata: information about the tweet, and information about the user. The twitter API includes a lot of this information. The API response has a lot of fields, and some of them change depending on the kind of tweet, so I won’t go into all of them. Instead I’ll just go over a few of the ones that interested me:
| Field | Description |
|---|---|
tweet/created_at |
Time of the tweet (UTC) |
tweet/text |
Full text of the tweet |
tweet/quoted_status OR tweet/retweeted_status |
When tweet contains another tweet, these fields contain information about the included tweet |
tweet/in_reply_to_status_id |
When tweet is a reply, contains the ID of the original tweet |
tweet/is_quote_status |
Boolean indicating whether the tweet quotes another tweet |
tweet/entities/user_mentions |
List of @handles in the tweet |
tweet/entities/media |
List of photos and videos in the tweet |
tweet/entities/urls |
List of URLs included in the tweet |
tweet/user/verified |
Boolean indicating verified users |
tweet/user/followers_count |
Integer counting the number of followers of tweeter |
tweet/user/statuses_count |
Integer counting the number of tweets the tweeter has tweeted |
tweet/user/default_profile |
Boolean indicating whether the tweeter is still using the defauly profile |
tweet/user/default_profile_image |
Boolean indicating whether the tweeter is still using the defauly profile picture |
tweet/user/description |
Tweeter bio |
tweet/user/friends_count |
Tweeter’s count of mutual followers |
Text analysis
I processed and standardized each tweet to facilitate machine learning…