
Scraping the search box on IMDB with Selenium
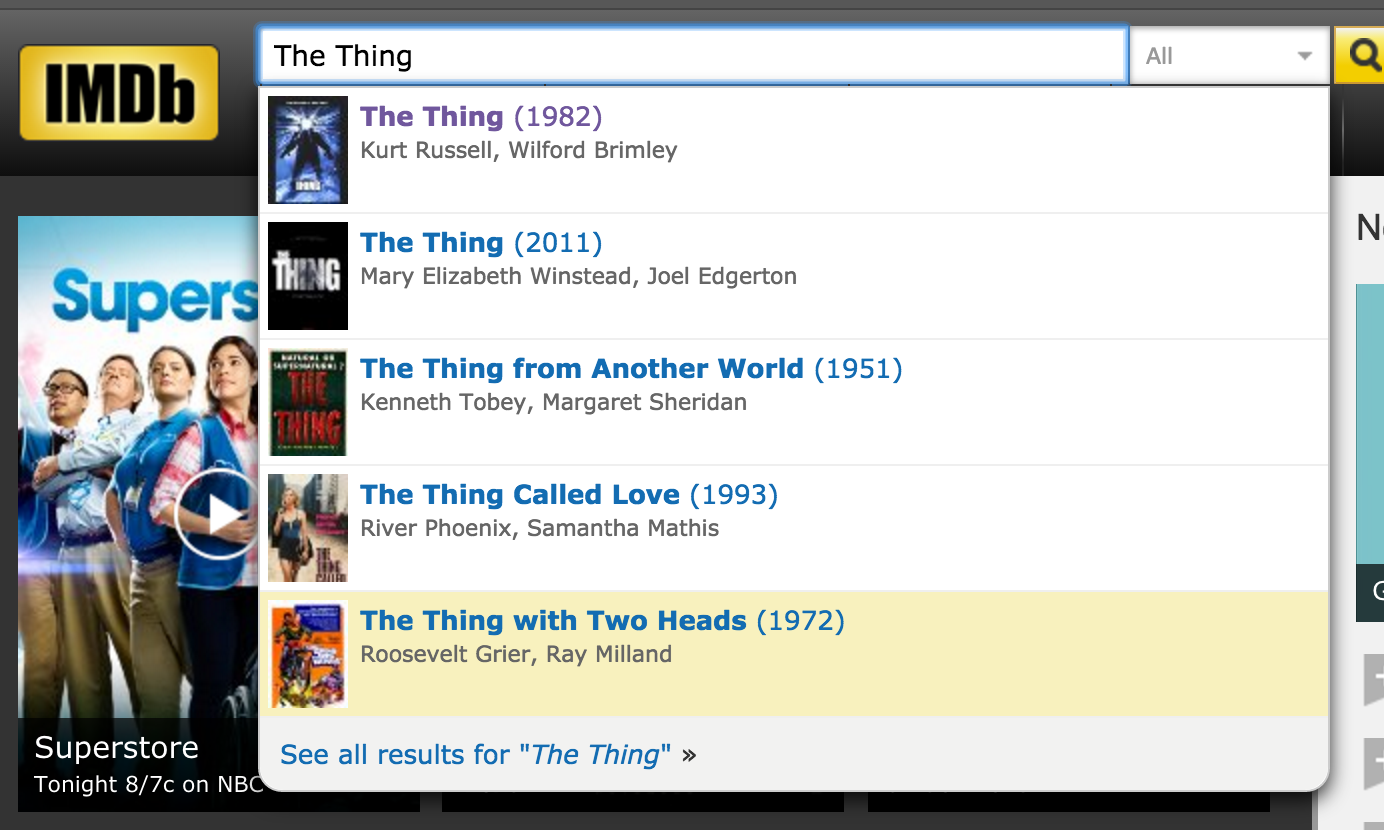
IMDB has an awesome auto-complete search box. Type some words in it, and it immediately shows you a list of movies that match your search. I wanted to see which movies I could find on IMDB without actually loading each page, so I decided to scrape information right out of the search box.
 |
This is beyond the capability of wget or requests, since the search box is implemented in Javascript, and they just download inactive HTML. I needed full browser capabilities, so I used Selenium to create a robotic instance of Firefox and scrape from it.
In order to use selenium, you need to download a driver first. I used a chrome driver, which I downloaded from the Selenium website. The driver is contained in a file called chromedriver which I put in the same directory as the python script.
Then you can import the driver
import os
from selenium import webdriver
chromedriver = "./chromedriver"
os.environ["webdriver.chrome.driver"] = chromedriver
driver = webdriver.Chrome(chromedriver)
Then you can open a page in Selenium. This will open an actual web browser, but a special ‘robo-browser’ that you can control from within python. For example, you can tell it to navigate to the page for ‘The Thing’:
thing_url = "http://www.imdb.com/title/tt0084787/"
driver.get(thing_url)
Now we need to select the search box so we can work with it. To do this, let’s look at the loaded page and right click the search box to inspect it.
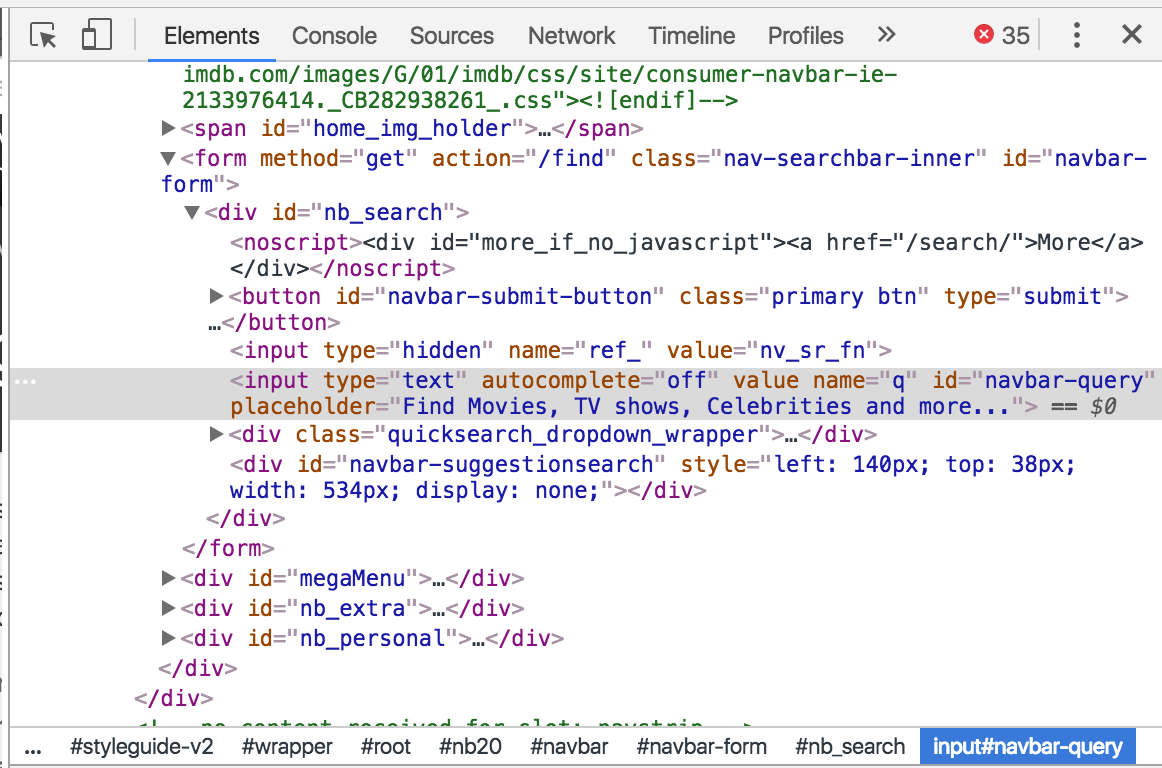 |
The search box’s id is navbar-query. Let’s select that element by id using Selenium:
searchbox = driver.find_element_by_id("navbar-query")
Now we can click on it and enter some text:
searchbox.click()
searchbox.send_keys("The Thing")
And the drop-down list appears! Inspecting the HTML like before, we find that it’s called navbar-suggestionsearch, so let’s select that element by id and have a look at the HTML
sug_html = driver.find_element_by_id('navbar-suggestionsearch').get_attribute('innerHTML')
print sug_html
And we get the HTML for the search box, which we will be able to parse to get the content:
<a href="/title/tt0084787/?ref_=nv_sr_1" class="poster">
<img src="https://images-na.ssl-images-amazon.com/images/M/MV5BMTRlMGIzYjItNTUwYS00OTc2LTk0ODktMGRjYWNlOTg3NzkwXkEyXkFqcGdeQXVyMTQxNzMzNDI@._V1._SX40_CR0,0,40,54_.jpg" style="background:url(\'http://i.media-imdb.com/images/mobile/film-40x54.png\')" width="40" height="54">
<div class="suggestionlabel">
<span class="title">The Thing</span> <span class="extra">(1982)</span>
<div class="detail">Kurt Russell, Wilford Brimley</div>
</div>
</a>
<a href="/title/tt0905372/?ref_=nv_sr_2" class="poster">
<img src="https://images-na.ssl-images-amazon.com/images/M/MV5BMTMxMjI0MzUyNl5BMl5BanBnXkFtZTcwNjc1NzE5NQ@@._V1._SX40_CR0,0,40,54_.jpg" style="background:url(\'http://i.media-imdb.com/images/mobile/film-40x54.png\')" width="40" height="54">
<div class="suggestionlabel">
<span class="title">The Thing</span> <span class="extra">(2011)</span>
<div class="detail">Mary Elizabeth Winstead, Joel Edgerton</div>
</div>
</a>
<a href="/title/tt0044121/?ref_=nv_sr_3" class="poster">
<img src="https://images-na.ssl-images-amazon.com/images/M/MV5BODA5MjE1MTY2Ml5BMl5BanBnXkFtZTgwNzU5MjQxMDE@._V1._SX40_CR0,0,40,54_.jpg" style="background:url(\'http://i.media-imdb.com/images/mobile/film-40x54.png\')" width="40" height="54">
<div class="suggestionlabel">
<span class="title">The Thing from Another World</span> <span class="extra">(1951)</span>
<div class="detail">Kenneth Tobey, Margaret Sheridan</div>
</div>
</a>
<a href="/title/tt0108327/?ref_=nv_sr_4" class="poster">
<img src="https://images-na.ssl-images-amazon.com/images/M/MV5BNDY1OTczNzc0OV5BMl5BanBnXkFtZTcwMzk1ODEzMQ@@._V1._SX40_CR0,0,40,54_.jpg" style="background:url(\'http://i.media-imdb.com/images/mobile/film-40x54.png\')" width="40" height="54">
<div class="suggestionlabel">
<span class="title">The Thing Called Love</span> <span class="extra">(1993)</span>
<div class="detail">River Phoenix, Samantha Mathis</div>
</div>
</a>
<a href="/title/tt0069372/?ref_=nv_sr_5" class="poster highlighted">
<img src="https://images-na.ssl-images-amazon.com/images/M/MV5BODg2NzUyNzAxOV5BMl5BanBnXkFtZTcwNzUyMzY3NA@@._V1._SX40_CR0,0,40,54_.jpg" style="background:url(\'http://i.media-imdb.com/images/mobile/film-40x54.png\')" width="40" height="54">
<div class="suggestionlabel">
<span class="title">The Thing with Two Heads</span> <span class="extra">(1972)</span>
<div class="detail">Roosevelt Grier, Ray Milland</div>
</div>
</a>
<a class="moreResults" href="/find?s=all&q=The Thing&ref_=nv_sr_sm"><span class="message">See all results for "<span class="query">The Thing</span>"</span> <span class="raquo">\xbb</span></a>
Now that we have the HTML, it’s time to parse it. Selenium is capable of parsing HTML, but it’s not easy or convenient to use. I used Selenium because I had to, but I prefer Beautiful Soup for parsing HTML. So I’ll pass that raw HTML along to Beautiful Soup and then parse out the data I’m interested in.
from bs4 import BeautifulSoup
soup=BeautifulSoup(sug_html, 'lxml')
Now Beautiful Soup has parsted the HTML, so we can find the stuff we want:
title = [x.text for x in soup.find_all('span', { "class" : "title" })]
year = [x.text for x in soup.find_all('span', { "class" : "extra" })]
detail = [x.text for x in soup.find_all('div', { "class" : "detail" })]
link = [x['href'] for x in soup.find_all('a')]
suggested_movies = zip(title, year, detail, link[:-1])
We got what we came for!
[('The Thing', '(1982)', 'Kurt Russell, Wilford Brimley', '/title/tt0084787/?ref_=nv_sr_1'),
('The Thing', '(2011)', 'Mary Elizabeth Winstead, Joel Edgerton', '/title/tt0905372/?ref_=nv_sr_2'),
('The Thing from Another World', '(1951)', 'Kenneth Tobey, Margaret Sheridan', '/title/tt0044121/?ref_=nv_sr_3'),
('The Thing Called Love', '(1993)', 'River Phoenix, Samantha Mathis', '/title/tt0108327/?ref_=nv_sr_4'),
('The Thing with Two Heads', '(1972)', 'Roosevelt Grier, Ray Milland', '/title/tt0069372/?ref_=nv_sr_5')]
Don’t let the door hit you on the way out:
driver.close()